
Accelerated view synthesis
In this post I want to introduce you to the topic of my bachelor thesis. I will try not to go too much into detail and try to describe it in a way everybody can understand it.
Accelerated Implementation of a View Synthesis Algorithm for 3D Video Sequences
The title sounds complicated, as it should be for a scientific work. So what is it about:
View-Synthesis
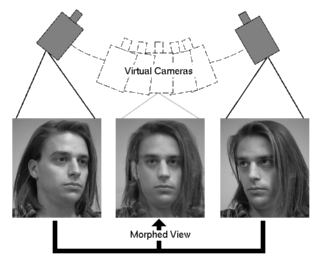
View-synthesis means that in a video sequence the camera position is changed afterwards and thus the observed scene can be shown from a different angle. What’s the point? Legitimate question. In the first place, the view-synthesis is used to transmit 3D video data. Note: Here one must not confuse 3D Video with the well known stereo video as in 3D cinemas. In contrast to stereo-video, where only two video streams for the right and left eye are showed, 3D video displays show many perspectives simultaneously. This is of course only possible with auto-stereoscopic displays. Depending on the angle you look at this display you will see a different image - without any annoying 3D glasses. However, in order to reduce the huge amount of data for all of these images, not all angles are getting transferred. Instead, we use view-synthesis to create these images afterwards. This is only possible if in addition to the video signals, depth or disparity maps are transferred. That means, that not only the color but also the distance to the camera is given for each pixel. The distance can be measured either with a special device, e.g. the Microsoft Kinect camera, or can be calculated in afterwards. 
Accelerated Implementation
I didn’t invent, nor extend or improve this method. My task was to improve the speed of the view-synthesis. I tried to achieve this by doing a large part of the calculations on the graphics card instead of on the CPU. Graphics cards have the advantage that they can do many similar calculations in parallel - that ‘s just what I need for view-synthesis.
What did I achieve?
For the actual application, namely “offline” view synthesis: calculate, store and watch afterwards - my implementation unfortunately did not bring a significant improvement. The reason for this is the data-transfer to the graphics card (and especially back again), which takes to long. However, if you don’t want to save the data, but show it directly on screen, my implementation performs quite good. Therefore I wrote a program that reads a 3D video and then performs a view-synthesis and displays the result in a window. The point of view (camera position) can be changed either with the mouse, or adapted to the position of your head by tracking with a webcam, while the video is playing.
Demo-Anwendung

My comments are in German, sorry.
The application was developed with Qt and OpenGL. The EHCI library was used for head-tracking. Only raw video data in YUV format can be played back. Depth maps are also necessary in addition to the videos. Some example sequences can be found on the FTP-server of the Fraunhofer Heinrich Hertz Institute.
- Server: ftp.hhi.de
- Verzeichnis: HHIMPEG3DV
- Benutzername: mpeg3dv
- Passwort: Cah#K9xu
Version 0.1 contains a config-file for the following YUV-Files:
Download
The Institute of Electrical Communication Engineering of the RWTH Aachen kindly allowed me to publish the source code. There is a Git repository on Sourceforge.
git clone git://git.code.sf.net/p/qtviewsynth/code qtviewsynth-code
You can also download the pre-build binaries.